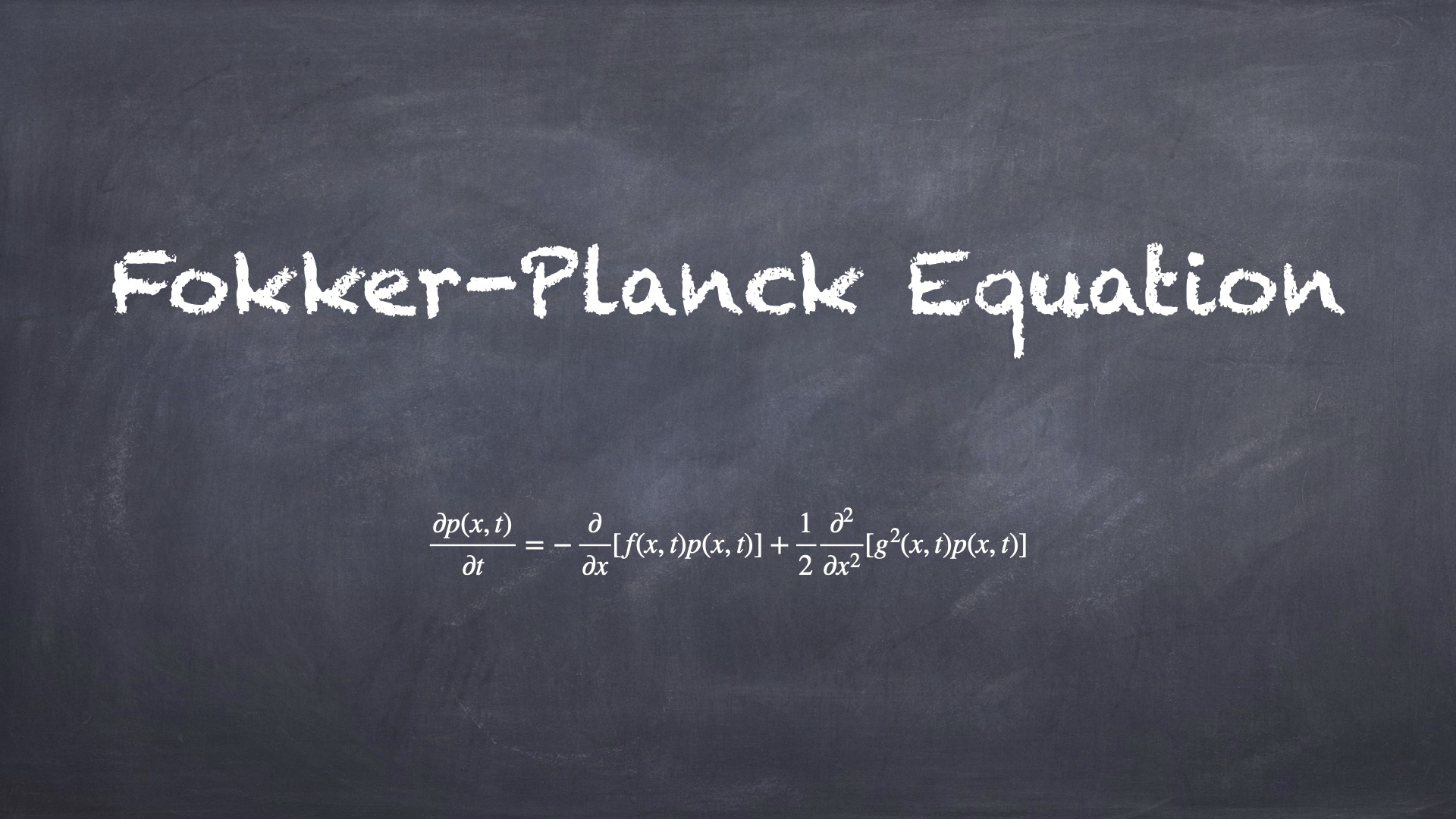Camera Models Pinhole Camera 小孔成像 如下图所示,当物体和墙面之间没有任何遮挡时,到达墙面上某一点的光来自于四面八方,其反射的光是所有到达该点的光的积分,因此整体上墙面只能呈现平均光强而不能成像。倘若在物体和墙面之间插入一个带有小孔的遮光平面,使得光线只能从小孔通过,那么到达墙面上某一点的光源就被限制在一个很小的范围,从而能在墙面上形成物体的倒像。 针孔相机 基于小孔成像原理,我们可以 2026-06-19 Computer Vision
T2I Benchmarks Setup 本文记录可直接 follow 不报错的常用文生图模型 benchmark 安装指南。 GenEval 论文|官方仓库 af4902f|重要参考 issue#12 环境设置 1、创建 conda 环境: 12conda create -n geneval -y python=3.8.10conda activate geneval 2、安装 torch 依赖: 1pip install torch= 2026-04-07 Deep Learning #deep learning
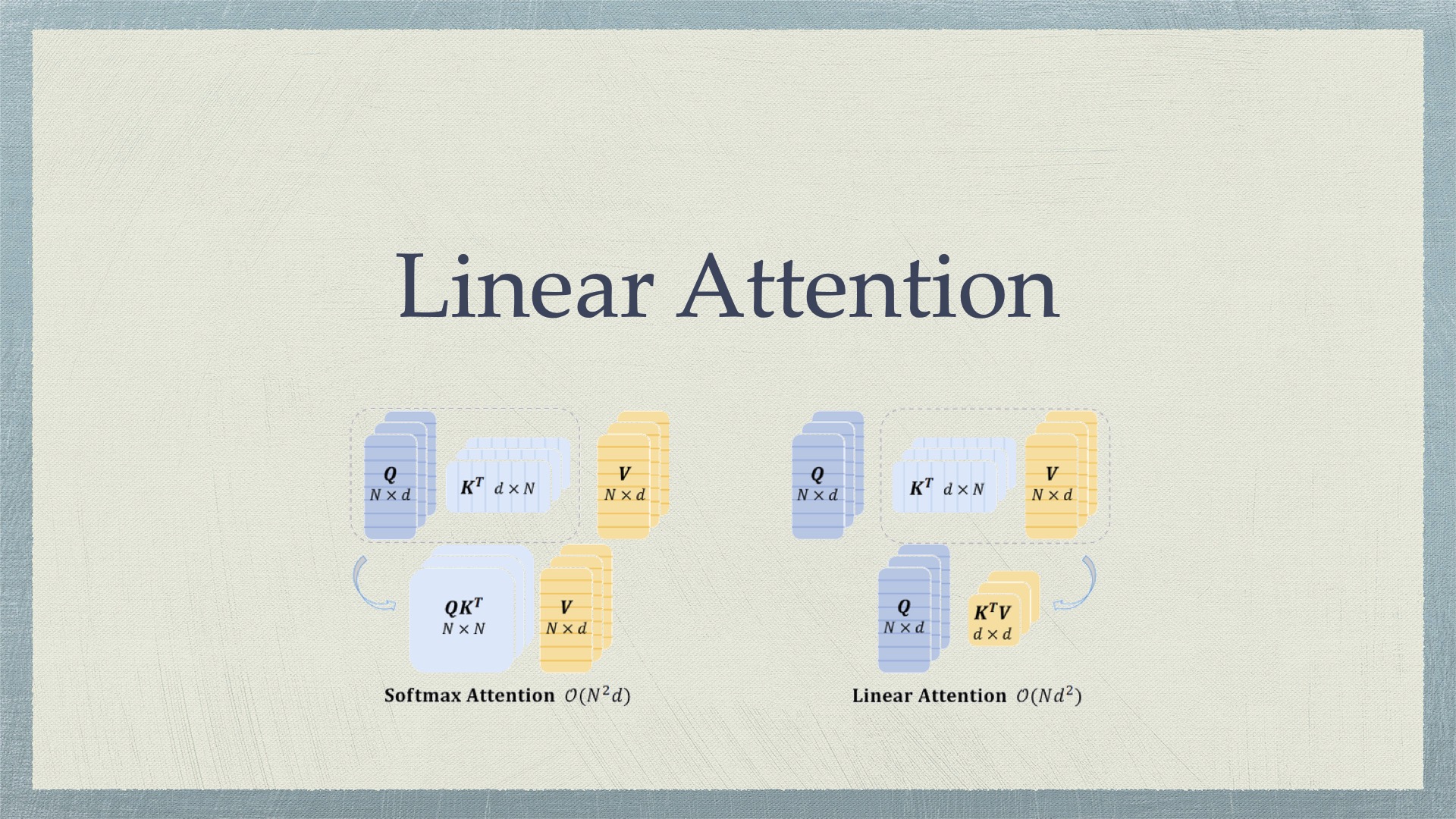
Linear Attention Softmax Attention 矩阵形式 设有 \(\mathbf Q,\mathbf K,\mathbf V\in\mathbb R^{n\times d}\),其中 \(n\) 表示序列长度,\(d\) 表示 token 维度。标准 softmax attention 的计算机制为: \[ \mathbf O=\text{softmax}\left(\frac{\mathbf Q\ma 2026-02-15 Deep Learning #deep learning
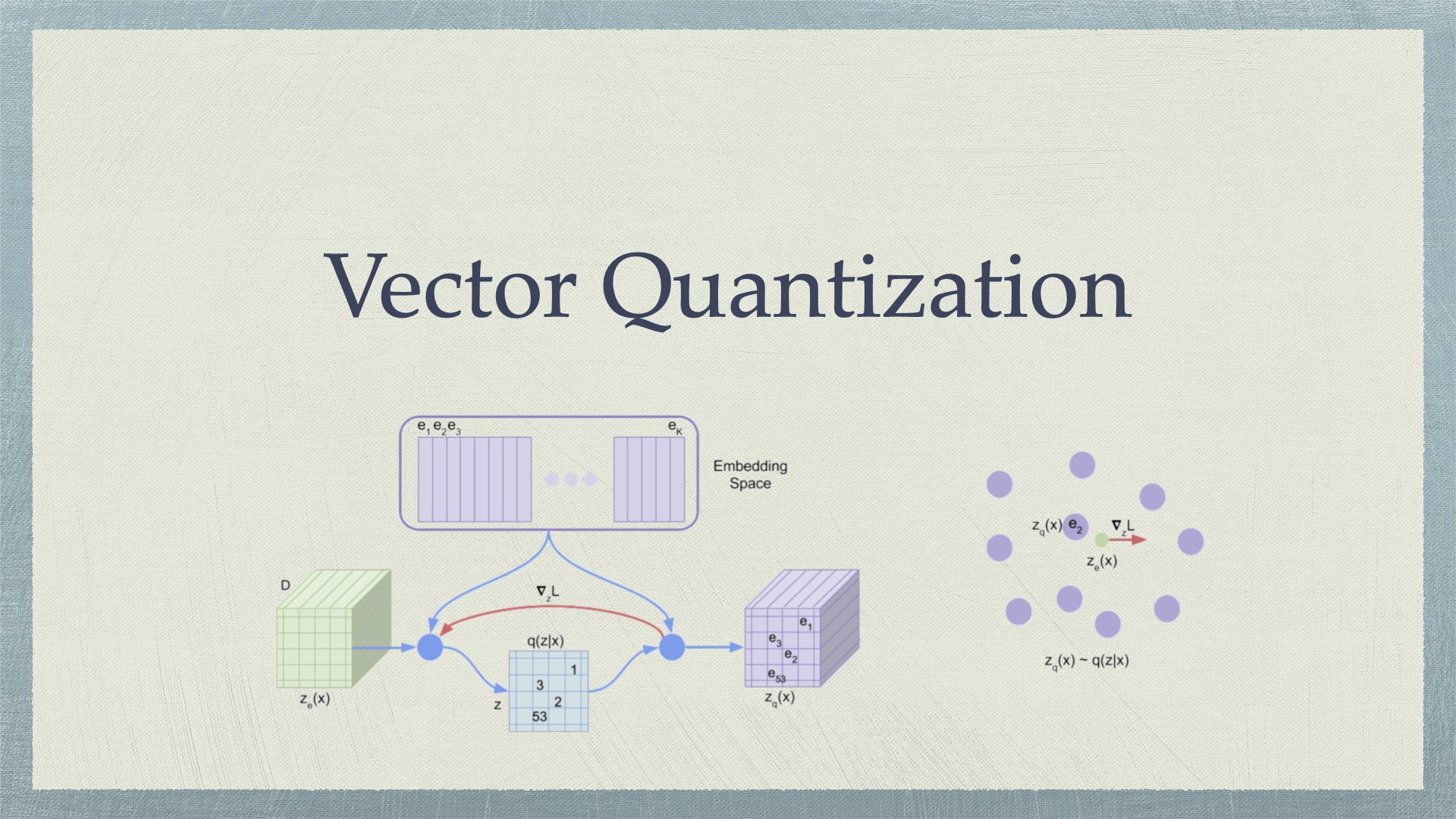
Vector Quantization VQ (STE) [NeurIPS 2017] [arXiv:1711.00937] Neural Discrete Representation Learning [CVPR 2021] [arXiv:2012.09841] Taming Transformers for High-Resolution Image Synthesis VQ (Gumbel Softmax) [ICLR 2 2026-01-21 Computer Vision
Diffusion Distillation Introduction 尽管扩散模型在生成质量、似然估计和训练稳定性上表现出卓越的性能,但其最大的缺点就是采样耗时。为此,许多采样器被提出以加速采样过程,例如 DDIM, Analytic-DPM, PNDM, DPM-Solver 等等,它们着眼于更精确地求解扩散 ODE,例如采用高阶的求解器并充分利用扩散 ODE 的特殊结构。然而,受制于模型本身的误差,此类 training-free 的方 2025-12-31 Generative Models > Diffusion Models #generative models
Training-Time CFG Background Classifier-Free Guidance (CFG) 能极大提升图像生成的质量,已成为了当下扩散与自回归图像生成的标准技术。 对扩散模型而言,设 \(\mathbf f_\theta\) 表示网络,可以是预测原图、噪声、分数或速度的任意一种参数化,其 CFG 实现为: \[ \mathbf f_\theta^\text{cfg}(\mathbf x_t,t\vert\ 2025-12-25 Generative Models > Diffusion Models #generative models
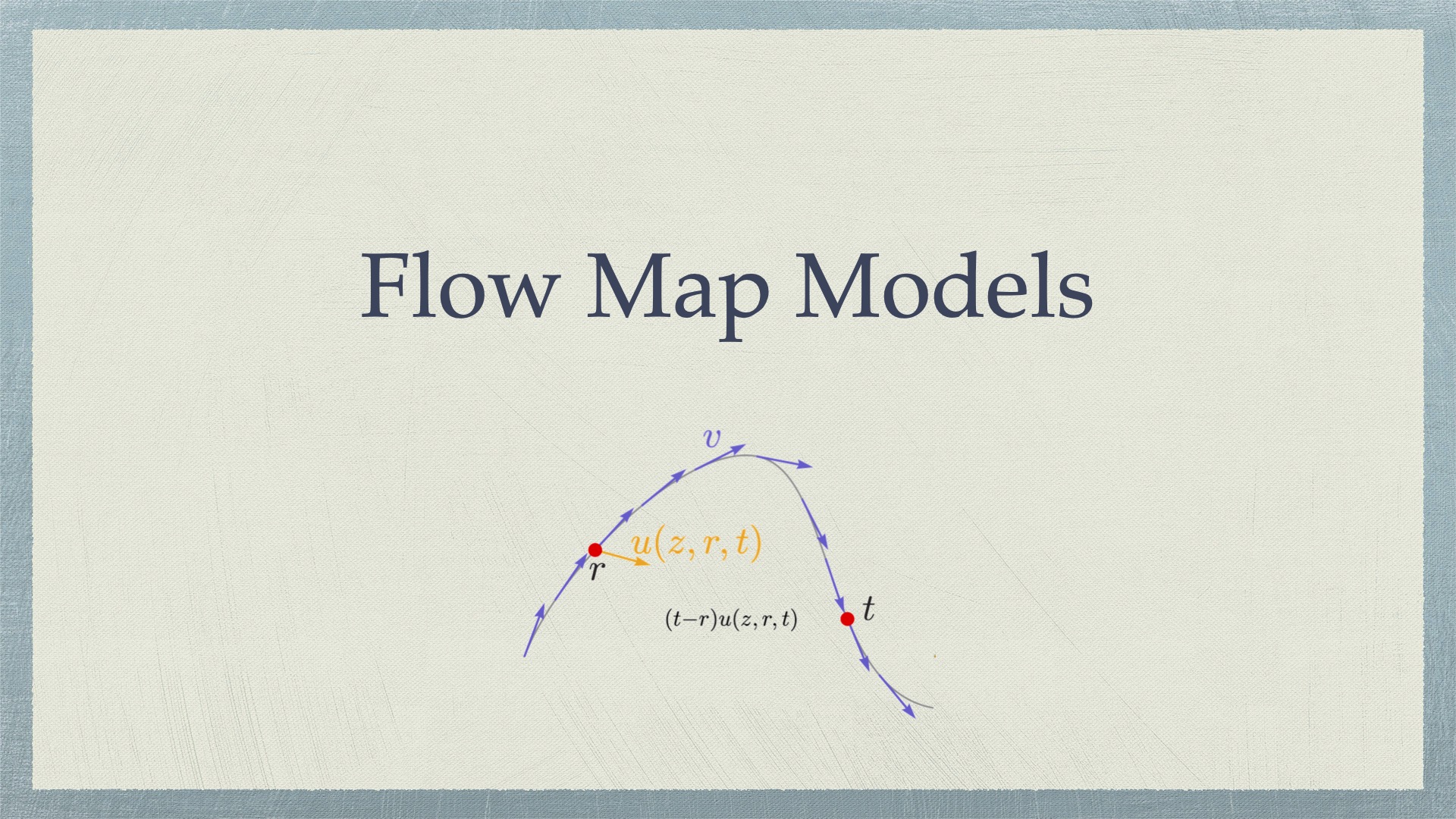
Flow Map Models 扩散/流模型最明显的短板就是迭代式生成的效率太低,为此人们做出了非常多的努力,大致可以分为以下三类: 改进采样器:提出 DDIM, Euler, Heun, DPM-Solver 等一阶或高阶 ODE/SDE 求解器。这类方法的优点在于无需训练,但是很难在 10 步采样以内保持图像质量。 模型蒸馏:以预训练扩散模型作为老师,蒸馏一个采样步数更少的学生模型,代表工作包括 Progressive D 2025-11-13 Generative Models > Diffusion Models #generative models
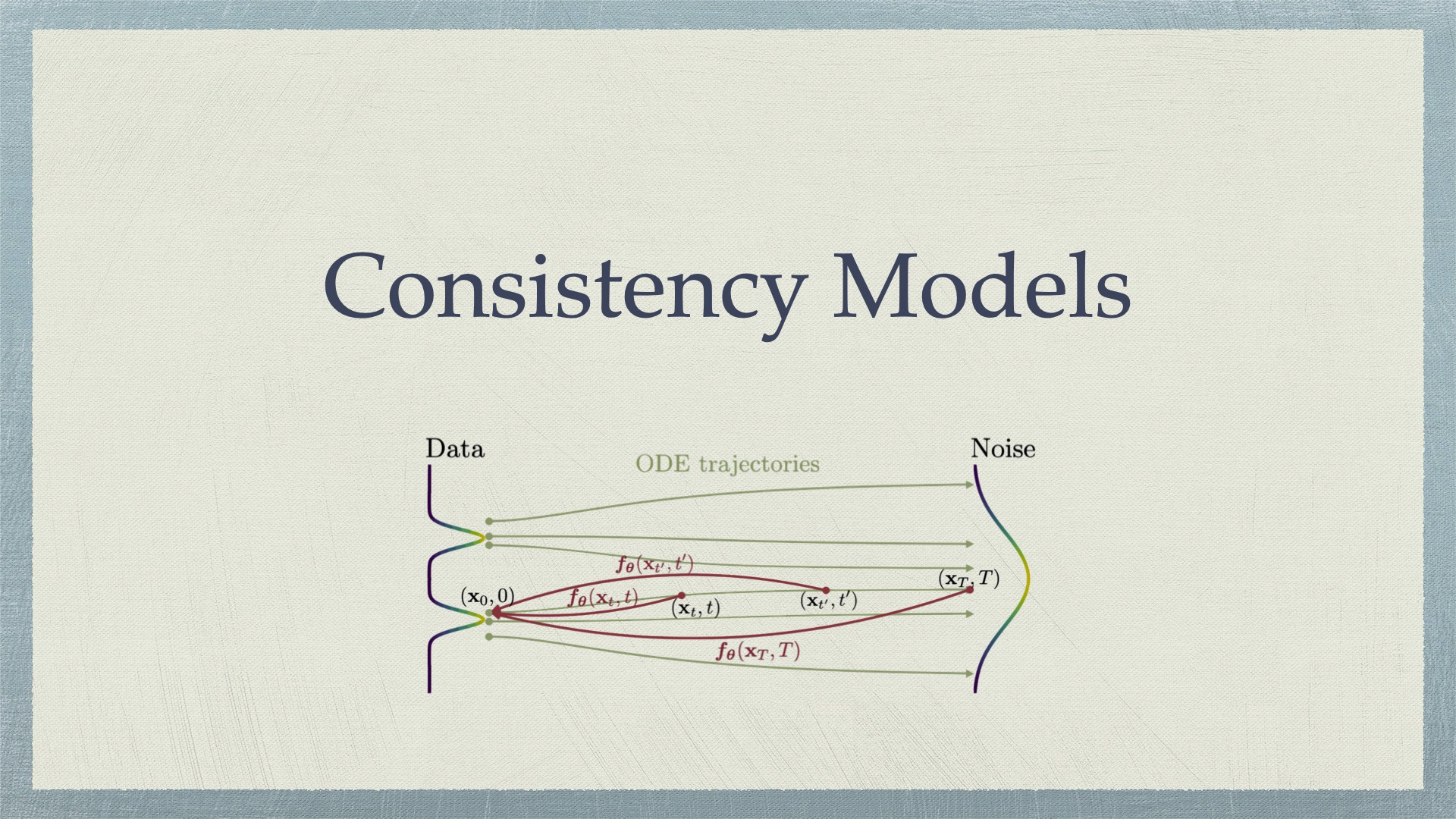
Consistency Models 本文介绍 Consistency Models 及其后续扩展,包括: CM: Consistency Models iCT: Improved Techniques for Training Consistency Models ECT: Consistency Models Made Easy CTM: Consistency Trajectory Models sCM: Simplifyin 2025-05-05 Generative Models > Diffusion Models #generative models
Reverse-Time SDE \[ \newcommand{\coloneqq}{\mathrel{\vcenter{:}}\mathrel{=}} \] 问题引入 考虑如下一维 SDE: \[ \mathrm dX_t=f(X_t,t)\mathrm dt+g(X_t,t)\mathrm dW_t \] 其 Fokker-Planck 方程 为: \[ \frac{\partial p(x,t)}{\partial t}=- 2025-02-25 Mathematics > Stochastic Process #stochastic process
Fokker-Planck Equation 一维情形 考察如下随机微分方程 (SDE): \[ \mathrm dX_t=f(X_t,t)\mathrm dt+g(X_t,t)\mathrm dW_t \] 其中 \(W_t\) 是维纳过程,\(f(X_t,t)\) 是 drift 系数,\(g(X_t,t)\) 是 diffusion 系数。Fokker-Planck 方程描述了满足该 SDE 的 \(X_t\) 的概率密度 \(p(x, 2025-02-20 Mathematics > Stochastic Process #stochastic process
Principal Component Analysis 主成分分析 主成分分析 (Principal Component Analysis, PCA) 是一种经典的数据降维方法。 推导:最小化近似误差 设有数据集 \(\{\mathbf x_n\}_{n=1}^N\),其中每个数据点 \(\mathbf x_n\in\mathbb R^d\). 不失一般性地,假设数据的均值为 \(0\),否则可以事先进行中心化。主成分分析希望找到 \(r\;(r< 2024-10-25 Machine Learning #machine learning
Order Statistic 求概率密度的微元法 若随机变量 \(X\) 的 PDF \(f(x)\) 在 \(x\) 处连续,则: \[ f(x)=\lim_{h\to 0}\frac{P(x< X\leq x+h)}{h} \] 或写作: \[ P(x<X\leq x+h)=f(x)h+o(h) \] 若随机向量 \((X_1,\ldots,X_n)\) 的 PDF \(f(x_1,\ldots,x_n)\) 2024-10-13 Mathematics > Probability and Statistics #statistics
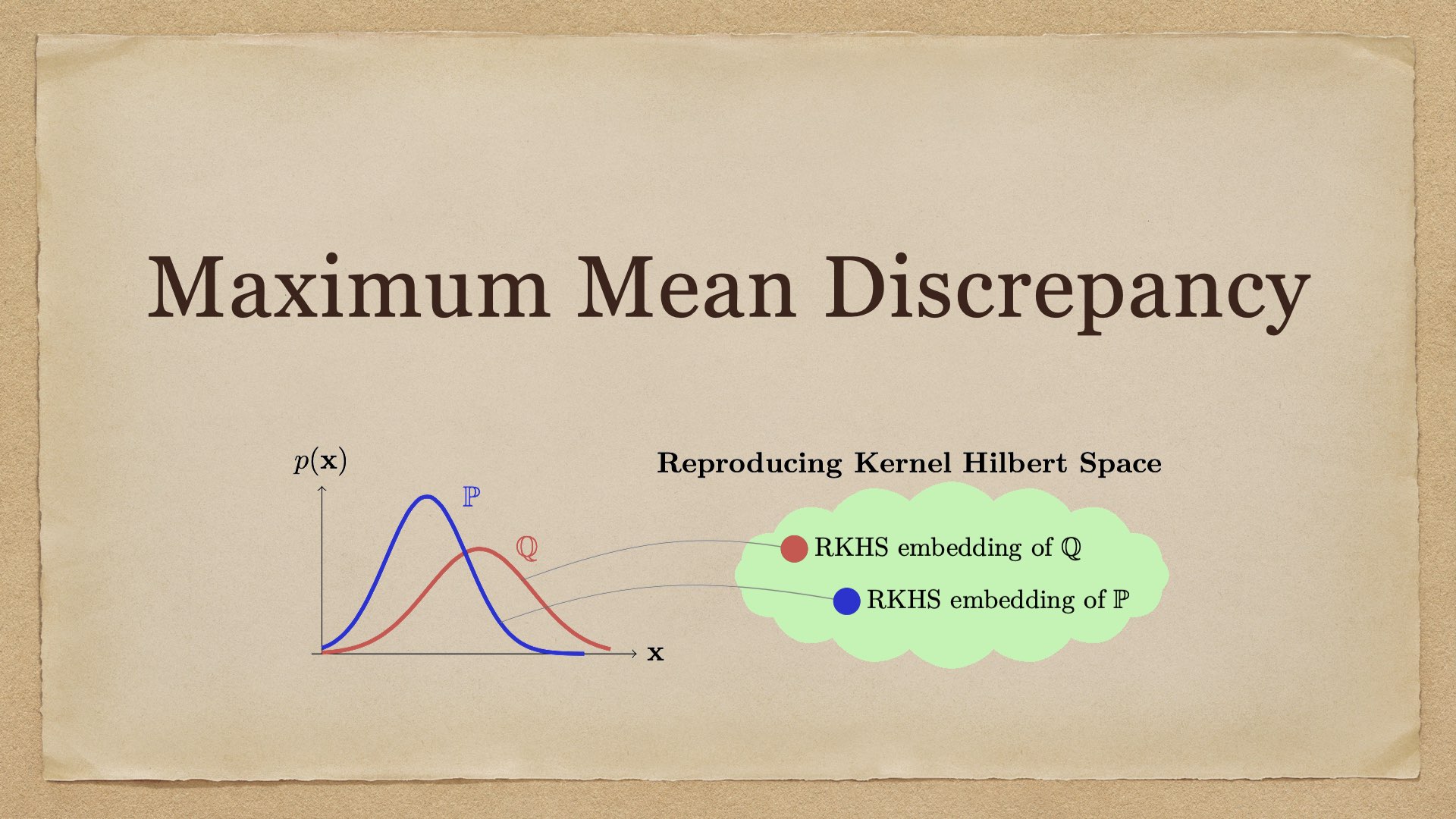
Maximum Mean Discrepancy 启发与定义 Maximum Mean Discrepancy (MMD) 是一个衡量两个分布差异的指标。具体而言,设 \(p,q\) 是 \(\mathcal X\) 上的概率分布,给定从 \(p\) 采样出的独立同分布样本 \(X=\{x_1,\ldots,x_m\}\) 以及从 \(q\) 采样出的独立同分布样本 \(Y=\{y_1,\ldots,y_n\}\),我们如何判断二者是否采样自同一 2024-07-08 Machine Learning #machine learning
个人网站维护 网站结构 123456xyfjason.github.io # 引导页├── xyfjason.github.io/homepage # 学术主页├── xyfjason.github.io/notes # 笔记├── xyfjason.github.io/blog-main # 主博客├── xyfjason.github.io/bl 2024-06-25 Tech Stack #blog
Flow Matching 连续归一化流 想象 \(\mathbb R^d\) 空间中有一系列粒子,在 \(t=0\) 时服从分布 \(p_0\),随时间流逝粒子在空间中流动,直至 \(t=1\) 时形成分布 \(p_1\). 于是这样的流动过程形成了从分布 \(p_0\) 到分布 \(p_1\) 的一个转换。如果我们能够为上述流体运动过程建立起模型,并控制 \(p_0\) 为某简单易采样分布而 \(p_1\) 服从数据分布 2024-06-22 Generative Models > Diffusion Models #generative models
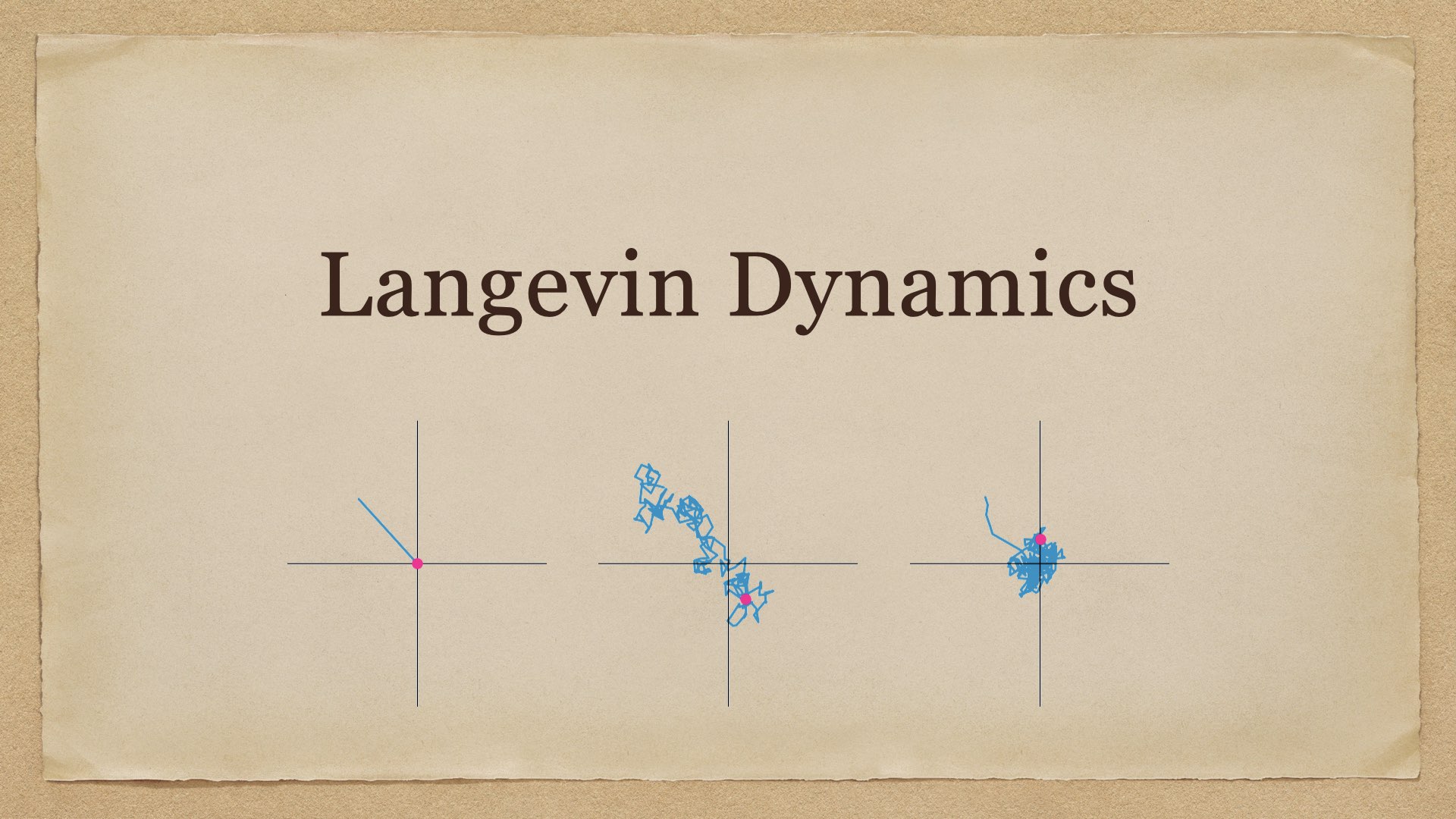
Langevin Dynamics 在 Score-Based Generative Models 一文中,我们用到了 Langevin dynamics 进行采样,但没有解释其原理。另外,在 Elucidated Diffusion Models 一文中,我们提到常用的扩散 SDE 和 PF ODE 其实可以推广为一个由 PF ODE 与 Langevin diffusion SDE 组合而成的广义 SDE. 由此可见,Lange 2024-06-21 Machine Learning #machine learning #stochastic process #physics
Lipschitz in Neural Network Lipschitz 连续性 实值函数情形 定义:设有函数 \(f:D\subset\mathbb R^n\to\mathbb R\),若存在常数 \(K\) 使得: \[ \vert f(\mathbf x)-f(\mathbf y)\vert\leq K\Vert \mathbf x- \mathbf y\Vert,\quad\forall\ \mathbf x, \mathbf y\in D 2024-06-19 Deep Learning #linear algebra #machine learning
Transformer's Positional Encoding 简介 众所周知,Transformer 中的注意力机制并不区分各个 token 的顺序,是置换不变的,因此在需要明确 token 顺序的场景下,我们必须人为地在 token 中注入位置信息,这就是位置编码 (positional encoding / embedding) 的作用。一般认为,理想的位置编码应该尽可能满足下列性质: 唯一性:每个位置都配备唯一的编码; 相对性:两个位置编码之间存在只 2024-06-10 Deep Learning #deep learning
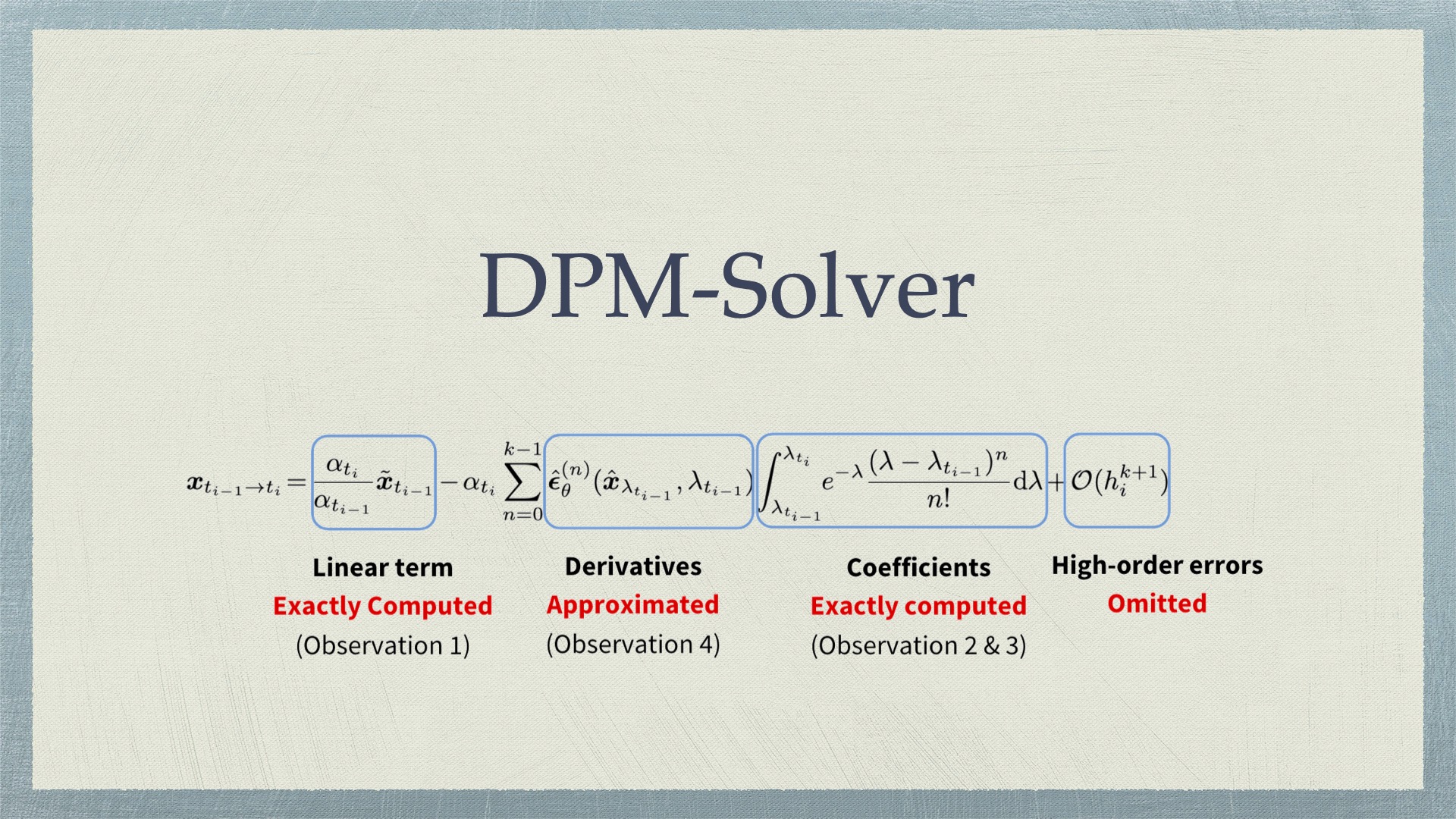
DPM-Solver DPM-Solver 从扩散 ODE 入手 相比扩散 SDE,由于扩散 ODE 没有随机性,更适合采用大步长以加速采样,因此本文作者只考虑扩散 ODE: \[ \mathrm d\mathbf x_t=\left[f(t)\mathbf x_t-\frac{1}{2}g^2(t)\nabla_{\mathbf x_t}\log q(\mathbf x_t)\right]\mathrm dt \] 2024-05-14 Generative Models > Diffusion Models #generative models
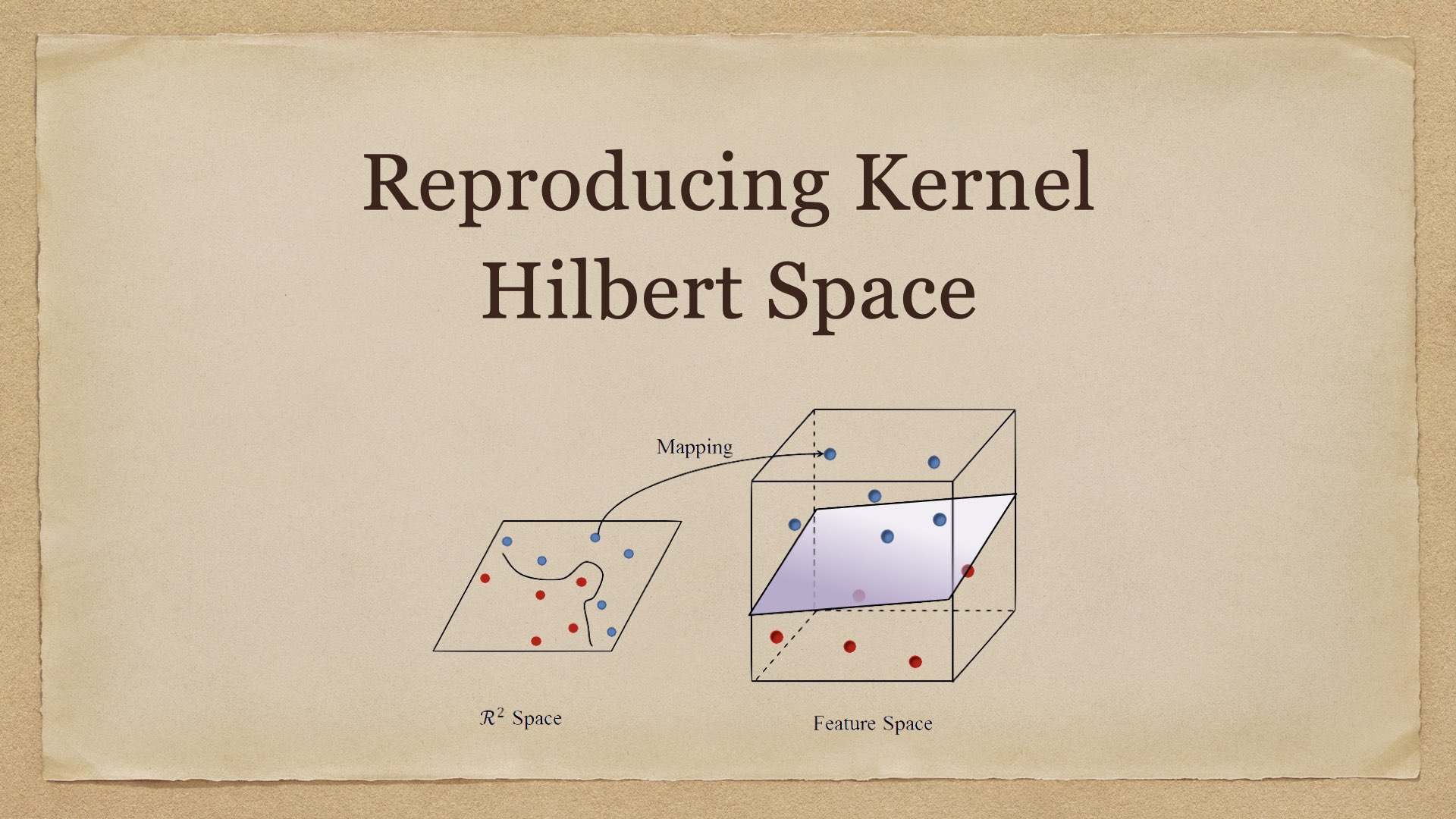
Reproducing Kernel Hilbert Space 引言 在学习 SVM 时,我们了解到了解决线性不可分问题的一种常用技巧——核方法。核方法的基本思想是,对于数据空间中线性不可分的样本,将它们映射到更高维度(甚至无穷维)的特征空间后就可以变成线性可分的。进一步地,我们引入了核函数来实现高维特征空间中的内积运算,而不需要先将数据点映射到特征空间后再算内积。 在之前的文章中,我们直接给出了几个常用核函数,但并没有说明怎样的函数可以成为核函数,核函数对应 2024-04-30 Machine Learning #machine learning