Flow Matching
连续归一化流
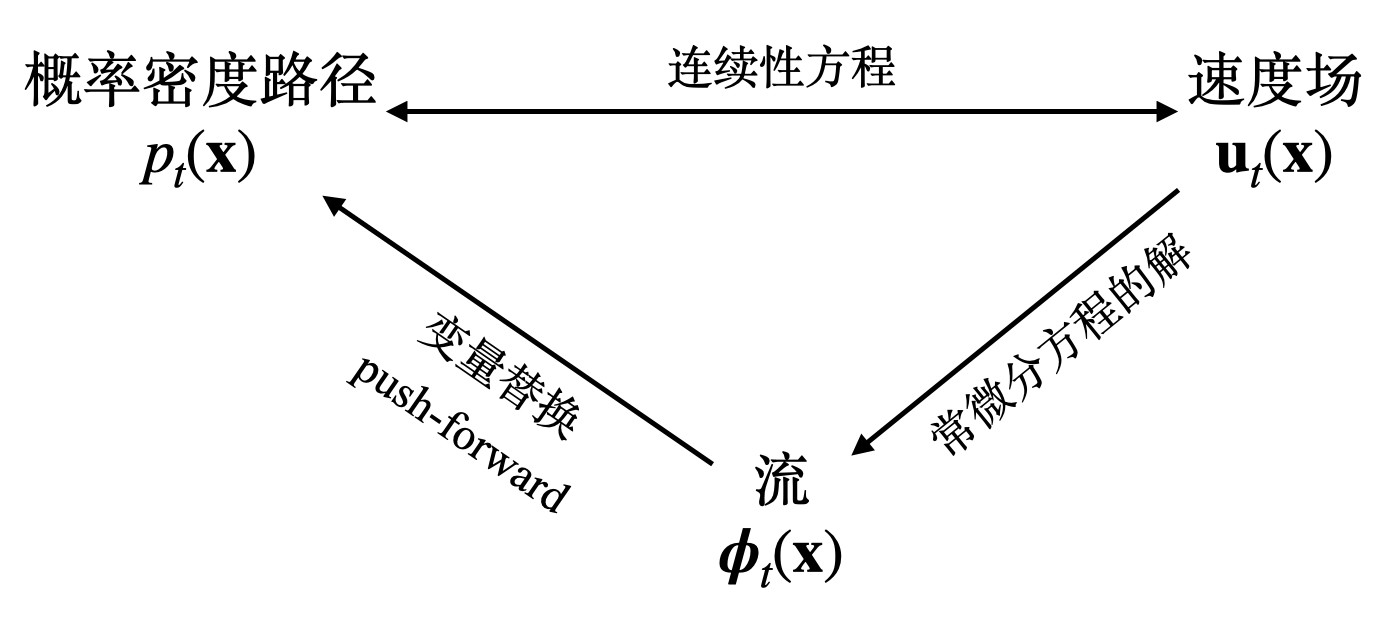
想象 \(\mathbb R^d\) 空间中有一系列粒子,在 \(t=0\) 时服从分布 \(p_0\),随时间流逝粒子在空间中流动,直至 \(t=1\) 时形成分布 \(p_1\). 于是这样的流动过程形成了从分布 \(p_0\) 到分布 \(p_1\) 的一个转换。如果我们能够为上述流体运动过程建立起模型,并控制 \(p_0\) 为某简单易采样分布而 \(p_1\) 服从数据分布,那么不就得到一个生成模型了吗?这样的生成模型称作连续归一化流 (Continuous Normalizing Flows, CNFs).
概率密度路径
粒子在流动的过程中,其概率分布在不断地改变。为描述各个时刻的概率分布,定义概率密度路径 (probability density path) 为: \[ p:[0,1]\times \mathbb R^d\to\mathbb R_{>0},\quad(t,\mathbf x)\mapsto p_t(\mathbf x) \] 其中 \(p_t(\mathbf x)\) 表示 \(t\) 时刻 \(\mathbf x\) 位置处的概率密度。称之为“路径”是因为 \(t\mapsto p_t\) 可以视作无限维概率分布空间中的流形上的一条路径。显然,对任意时刻 \(t\in[0,1]\),概率密度 \(p_t(\mathbf x)\) 都应满足归一化条件:\(\int p_t(\mathbf x)\mathrm d\mathbf x=1\). 因此,区别于一般的流体,我们称这种模型为归一化流;又由于时间是连续的,因此称为连续归一化流。
速度场与连续性方程
考虑空间中粒子在各个时刻的瞬时速度,定义速度场 (velocity field) 为: \[ \mathbf u:[0,1]\times\mathbb R^d\to\mathbb R^d,\quad (t,\mathbf x)\mapsto \mathbf u_t(\mathbf x) \] 其中 \(\mathbf u_t(\mathbf x)\) 表示 \(t\) 时刻 \(\mathbf x\) 位置处粒子的运动速度。流体中的粒子沿着速度场 \(\mathbf u\) 运动,引起概率密度的变化,因此 \(\mathbf u_t(\mathbf x)\) 与 \(p_t(\mathbf x)\) 之间一定存在某种关系,这个关系式称为连续性方程 (continuity equation): \[ \frac{\partial}{\partial t}p_t(\mathbf x)+\nabla\cdot(p_t(\mathbf x)\mathbf u_t(\mathbf x))=0 \] 直观上,连续性方程的第一项表示单位时间内 \(\mathbf x\) 位置处粒子的增加/减少量,第二项表示单位时间内 \(\mathbf x\) 位置处粒子的流出/流入量,由于粒子增加量就是流入量,因此连续性方程成立。熟悉随机微分方程的读者可能会发现,连续性方程其实就是 Fokker-Planck 方程在扩散项为零时的情形。
值得注意的是,概率密度路径与速度场不是一一对应的关系,不同的速度场可以产生相同的概率密度路径。例如,给 \(\mathbf u_t(\mathbf x)\) 加上散度为零的场(无源场),就得到了一个新的速度场,并且连续性方程依旧成立,所以概率密度路径不变。
流与 push-forward 方程
粒子沿着速度场运动,得到的轨迹称为流 (flow)。具体而言,定义流为: \[ \boldsymbol\phi:[0,1]\times\mathbb R^d\to\mathbb R^d,\quad (t,\mathbf x)\mapsto\boldsymbol\phi_t(\mathbf x) \] 其中 \(\boldsymbol\phi_t(\mathbf x)\) 表示 \(0\) 时刻位于 \(\mathbf x\) 处的粒子在 \(t\) 时刻运动到的位置。换句话说,随着 \(t\) 从 0 到 1 变化,\(\boldsymbol\phi_t(\mathbf x)\) 形成了从 \(\mathbf x\) 位置出发的粒子运动的轨迹。给定速度场 \(\mathbf u\),流由下述常微分方程给出: \[ \frac{\mathrm d}{\mathrm dt}\boldsymbol\phi_t(\mathbf x)=\mathbf u_t(\boldsymbol\phi_t(\mathbf x)),\quad\boldsymbol\phi_0(\mathbf x)=\mathbf x \] 为了看得更清楚,对上式左右两边同时从 \(0\) 到 \(t\) 积分得 \(\boldsymbol\phi_t(\mathbf x)-\mathbf x=\int_0^t\mathbf u_s(\boldsymbol\phi_s(\mathbf x))\mathrm ds\),左边表示从 \(\mathbf x\) 出发的粒子在 \(t\) 时间内的位移,右边是对速度的积分,自然也是位移。
根据流 \(\boldsymbol\phi\) 的定义,\(t\) 时刻位于 \(\mathbf x\) 位置处的粒子在 \(0\) 时刻的出发位置是 \(\boldsymbol\phi_t^{-1}(\mathbf x)\),因此根据随机变量的变量替换 (change of variables) 公式,可以知道 \(p_t(\mathbf x)\) 与 \(\boldsymbol\phi_t(\mathbf x)\) 之间有关系: \[ p_t(\mathbf x)=p_0(\boldsymbol\phi_t^{-1}(\mathbf x))\left|\det\left[\frac{\partial}{\partial\mathbf x}\boldsymbol\phi_t^{-1}(\mathbf x)\right]\right| \] 该式可简记作 \(p_t=[\boldsymbol\phi_t]_\#(p_0)\),称作 push-forward 方程。
综上所述,概率密度路径 \(p_t(\mathbf x)\)、速度场 \(\mathbf u_t(\mathbf x)\) 和流 \(\boldsymbol\phi_t(\mathbf x)\) 之间的关系可表示为下图:
拓展:瞬时变量替换公式
Push-forward 方程给出了 \(0\) 时刻到 \(t\) 时刻概率密度的变化。进一步地,Neural ODE 的作者还给出了描述 \(t\) 时刻概率密度瞬时变化的微分方程,称作瞬时变量替换公式 (instantaneous change of variables): \[ \frac{\mathrm d}{\mathrm dt}\log p_t(\boldsymbol\phi_t(\mathbf x))+\nabla\cdot\mathbf u_t(\boldsymbol\phi_t(\mathbf x))=0 \]
推导:计算 \(p_t(\boldsymbol\phi_t(\mathbf x))\) 对 \(t\) 的全导数: \[\begin{align}\frac{\mathrm d}{\mathrm dt}p_t(\boldsymbol\phi_t(\mathbf x))&=\left.\frac{\partial}{\partial t}p_t(\mathbf y)\right|_{\mathbf y=\boldsymbol\phi_t(\mathbf x)}+\left\langle\left.\nabla p_t(\mathbf y)\right|_{\mathbf y=\boldsymbol\phi_t(\mathbf x)},\frac{\mathrm d\boldsymbol\phi_t(\mathbf x)}{\mathrm dt}\right\rangle\\&=-\left.\nabla\cdot(p_t(\mathbf y)\mathbf u_t(\mathbf y))\right|_{\mathbf y=\boldsymbol\phi_t(\mathbf x)}+\left\langle\nabla p_t(\boldsymbol\phi_t(\mathbf x)),\frac{\mathrm d\boldsymbol\phi_t(\mathbf x)}{\mathrm dt}\right\rangle\\&=-\big[p_t(\mathbf y)(\nabla\cdot\mathbf u_t(\mathbf y))+\langle\nabla p_t(\mathbf y),\mathbf u_t(\mathbf y)\rangle\big]\Big|_{\mathbf y=\boldsymbol\phi_t(\mathbf x)}+\left\langle\nabla p_t(\boldsymbol\phi_t(\mathbf x)),\frac{\mathrm d\boldsymbol\phi_t(\mathbf x)}{\mathrm dt}\right\rangle\\\\&=-p_t(\boldsymbol\phi_t(\mathbf x))(\nabla\cdot\mathbf u_t(\boldsymbol\phi_t(\mathbf x)))-\left\langle\nabla p_t(\boldsymbol\phi_t(\mathbf x)),\mathbf u_t(\boldsymbol\phi_t(\mathbf x))\right\rangle+\left\langle\nabla p_t(\boldsymbol\phi_t(\mathbf x)),\frac{\mathrm d\boldsymbol\phi_t(\mathbf x)}{\mathrm dt}\right\rangle\\&=-p_t(\boldsymbol\phi_t(\mathbf x))(\nabla\cdot\mathbf u_t(\boldsymbol\phi_t(\mathbf x)))\end{align}\] 其中第二行是代入了连续性方程,第三行是将散度展开,最后一行是代入流的定义。于是: \[\frac{\mathrm d}{\mathrm d t}\log p_t(\boldsymbol\phi_t(\mathbf x))=\frac{1}{p_t(\boldsymbol\phi_t(\mathbf x))}\frac{\mathrm d}{\mathrm dt}p_t(\boldsymbol\phi_t(\mathbf x))=-\nabla\cdot\mathbf u_t(\boldsymbol\phi_t(\mathbf x))\] 这就得到了瞬时变量替换公式。
Flow Matching
设 \(p_t(\mathbf x)\) 是一概率密度路径,满足 \(p_0\) 为某简单分布(例如标准正态分布)且 \(p_1\) 为数据分布。设 \(\mathbf u_t(\mathbf x)\) 为能导出该概率密度路径的速度场。Flow matching 使用神经网络构建速度场 \(\mathbf v_{t}(\mathbf x;\theta)\) 去近似真实速度场 \(\mathbf u_t(\mathbf x)\),损失函数为: \[ \mathcal L_\text{FM}(\theta)=\mathbb E_{t,p_t(\mathbf x)}\left[\Vert\mathbf v_{t}(\mathbf x;\theta)-\mathbf u_t(\mathbf x)\Vert^2\right] \] 然而式中真实速度场 \(\mathbf u_t(\mathbf x)\) 是未知的,因此我们无法直接使用上式训练网络。如果读者对 score matching 比较熟悉的话,会发现这里遇到的问题与 score matching 非常类似,而解决方案也是类似的:在每一轮迭代中,网络只去近似给定单个样本条件下的条件速度场,经过多轮迭代均摊后网络即可收敛到无条件的真实速度场。
条件概率路径与条件速度场
具体而言,给定某特定样本 \(\mathbf x_1\),定义条件概率路径为 \(p_t(\mathbf x\vert\mathbf x_1)\),则边缘概率路径为所有条件概率路径的期望: \[ p_t(\mathbf x)=\int p_t(\mathbf x\vert\mathbf x_1)q(\mathbf x_1)\mathrm d\mathbf x_1=\mathbb E_{q(\mathbf x_1)}[p_t(\mathbf x\vert\mathbf x_1)] \] 又设上述条件概率路径 \(p_t(\mathbf x\vert\mathbf x_1)\) 可以由条件速度场 \(\mathbf u_t(\mathbf x\vert\mathbf x_1)\) 得到(即二者满足连续性方程),那么可以推得,边缘速度场 \(\mathbf u_t(\mathbf x)\) 与条件速度场 \(\mathbf u_t(\mathbf x\vert\mathbf x_1)\) 应有如下关系: \[ \mathbf u_t(\mathbf x)=\int \mathbf u_t(\mathbf x\vert\mathbf x_1)\frac{p_t(\mathbf x\vert\mathbf x_1)q(\mathbf x_1)}{p_t(\mathbf x)}\mathrm d\mathbf x_1=\mathbb E_{p(\mathbf x_1\vert\mathbf x)}[\mathbf u_t(\mathbf x\vert\mathbf x_1)] \]
证明:我们只需要证明基于上面的方式定义的 \(\mathbf u_t(\mathbf x)\) 与 \(p_t(\mathbf x)\) 满足连续性方程即可。直接代入: \[\begin{align}\frac{\partial p_t(\mathbf x)}{\partial t}&=\int\left(\frac{\partial}{\partial t}p_t(\mathbf x\vert\mathbf x_1)\right)q(\mathbf x_1)\mathrm d\mathbf x_1\\&=-\int\nabla\cdot (p_t(\mathbf x\vert\mathbf x_1)\mathbf u_t(\mathbf x\vert\mathbf x_1))q(\mathbf x_1)\mathrm d\mathbf x_1\\&=-\nabla\cdot\left(\int p_t(\mathbf x\vert\mathbf x_1)\mathbf u_t(\mathbf x\vert\mathbf x_1)q(\mathbf x_1) \mathrm d\mathbf x_1\right)\\&=-\nabla\cdot (p_t(\mathbf x)\mathbf u_t(\mathbf x))\end{align}\] 证毕。
CFM 损失函数
基于条件概率路径和条件速度场,原始的 flow matching 损失函数可以改写作如下 conditional flow matching 损失函数: \[ \mathcal L_\text{CFM}(\theta)=\mathbb E_{t,q(\mathbf x_1),p_t(\mathbf x\vert\mathbf x_1)}\left[\Vert\mathbf v_{t}(\mathbf x;\theta)-\mathbf u_t(\mathbf x\vert\mathbf x_1)\Vert^2\right] \] 可以证明 \(\mathcal L_\text{FM}\) 与 \(\mathcal L_\text{CFM}\) 只差与 \(\theta\) 无关的常数,因此对优化问题而言是等价的。
证明:将 \(\mathcal L_\text{FM}\) 中的平方打开: \[\mathcal L_\text{FM}(\theta)=\mathbb E_{t,p_t(\mathbf x)}\left[\Vert\mathbf v_{t}(\mathbf x;\theta)\Vert^2\right]+\mathbb E_{t,p_t(\mathbf x)}\left[\Vert\mathbf u_t(\mathbf x)\Vert^2\right]-2\mathbb E_{t,p_t(\mathbf x)}\left[\left\langle\mathbf v_t(\mathbf x;\theta),\mathbf u_t(\mathbf x)\right\rangle\right]\] 第一项保留,第二项与 \(\theta\) 无关扔掉,第三项做如下变形: \[\begin{align}\mathbb E_{p_t(\mathbf x)}\left[\left\langle\mathbf v_t(\mathbf x;\theta),\mathbf u_t(\mathbf x)\right\rangle\right]&=\int p_t(\mathbf x)\left\langle\mathbf v_t(\mathbf x;\theta),\int \mathbf u_t(\mathbf x\vert\mathbf x_1)\frac{p_t(\mathbf x\vert\mathbf x_1)q(\mathbf x_1)}{p_t(\mathbf x)}\mathrm d\mathbf x_1\right\rangle\mathrm d\mathbf x\\&=\int\left\langle\mathbf v_t(\mathbf x;\theta),\int \mathbf u_t(\mathbf x\vert\mathbf x_1)p_t(\mathbf x\vert\mathbf x_1)q(\mathbf x_1)\mathrm d\mathbf x_1\right\rangle\mathrm d\mathbf x\\&=\iint\left\langle\mathbf v_t(\mathbf x;\theta),\mathbf u_t(\mathbf x\vert\mathbf x_1)\right\rangle p_t(\mathbf x\vert\mathbf x_1)q(\mathbf x_1)\mathrm d\mathbf x_1\mathrm d\mathbf x\\&=\mathbb E_{q(\mathbf x_1),p_t(\mathbf x\vert\mathbf x_1)}\left[\left\langle\mathbf v_t(\mathbf x;\theta),\mathbf u_t(\mathbf x\vert\mathbf x_1)\right\rangle\right]\end{align}\] 加上第一项得: \[\mathcal L_\text{CFM}(\theta)=\mathbb E_{t,q(\mathbf x_1),p_t(\mathbf x\vert\mathbf x_1)}\left[\Vert\mathbf v_{t}(\mathbf x;\theta)\Vert^2-2\left\langle\mathbf v_t(\mathbf x;\theta),\mathbf u_t(\mathbf x\vert\mathbf x_1)\right\rangle\right]\] 形式不太好看,我们配个方将其写成 MSE,就得到了 CFM 损失函数: \[\mathcal L_\text{CFM}(\theta)=\mathbb E_{t,q(\mathbf x_1),p_t(\mathbf x\vert\mathbf x_1)}\left[\Vert\mathbf v_{t}(\mathbf x;\theta)-\mathbf u_t(\mathbf x\vert\mathbf x_1)\Vert^2\right]\]
Gaussian Flow Matching
前文讲得都是抽象的理论,本节研究一种具体的实例化。考虑高斯分布形式的条件概率路径: \[ p_t(\mathbf x\vert\mathbf x_1)=\mathcal N\left(\mathbf x;\boldsymbol\mu_t(\mathbf x_1),\sigma_t^2(\mathbf x_1)\mathbf I\right) \] 其中 \(\boldsymbol\mu:[0,1]\times \mathbb R^d\to\mathbb R^d\) 为与时间步有关的均值,\(\sigma:[0,1]\times\mathbb R^d\to\mathbb R_{>0}\) 为与时间步有关的标准差,并且规定:
- 当 \(t=0\) 时,应有 \(p_0(\mathbf x\vert\mathbf x_1)=\mathcal N(\mathbf x;\mathbf0,\mathbf I)\),即与 \(\mathbf x_1\) 无关的标准高斯分布;
- 当 \(t=1\) 时,应有 \(p_1(\mathbf x\vert\mathbf x_1)=\mathcal N\left(\mathbf x;\mathbf x_1,\sigma_\min^2\mathbf I\right)\),其中 \(\sigma_\min\) 充分小,使其大约是在 \(\mathbf x_1\) 处的确定性分布。
直观上,当 \(t\) 从 \(0\) 到 \(1\) 变化时,我们定义了一个从标准高斯到集中于 \(\mathbf x_1\) 处的高斯的分布变化过程。有无数种流都可以产生这样的分布变化过程,我们选取最为简单的一种: \[ \boldsymbol\psi_t(\mathbf x)=\sigma_t(\mathbf x_1)\mathbf x+\boldsymbol\mu_t(\mathbf x_1) \] 可以验证上述形式的条件流 \(\boldsymbol\psi_t\) 与条件概率路径 \(p_t(\mathbf x\vert\mathbf x_1)\) 的确满足变量替换公式: \[ \begin{align} p_0(\boldsymbol\psi_t^{-1}(\mathbf x)\vert\mathbf x_1)\left|\det\left[\frac{\partial\boldsymbol\psi_t^{-1}}{\partial\mathbf x}(\mathbf x)\right]\right|&= p(\boldsymbol\psi_t^{-1}(\mathbf x))\left|\det\left[\frac{\partial\boldsymbol\psi_t^{-1}}{\partial\mathbf x}(\mathbf x)\right]\right|\\ &=\mathcal N\left(\frac{\mathbf x-\boldsymbol\mu_t(\mathbf x_1)}{\sigma_t(\mathbf x_1)};\mathbf0,\mathbf I\right)\left|\frac{1}{\sigma_t^d(\mathbf x_1)}\right|\\ &=\mathcal N\left(\mathbf x;\boldsymbol\mu_t(\mathbf x_1),\sigma_t^2(\mathbf x_1)\mathbf I\right)\\ &=p_t(\mathbf x\vert\mathbf x_1) \end{align} \] 用条件流重参数化 \(\mathbf x\),可得损失函数为: \[ \begin{align} \mathcal L_\text{CFM}(\theta)&=\mathbb E_{t,q(\mathbf x_1),p_t(\mathbf x\vert\mathbf x_1)}\left[\Vert\mathbf v_{t}(\mathbf x;\theta)-\mathbf u_t(\mathbf x\vert\mathbf x_1)\Vert^2\right]\\ &=\mathbb E_{t,q(\mathbf x_1),p(\mathbf x_0)}\left[\Vert\mathbf v_{t}(\boldsymbol\psi_t(\mathbf x_0);\theta)-\mathbf u_t(\boldsymbol\psi_t(\mathbf x_0)\vert\mathbf x_1)\Vert^2\right]\\ &=\mathbb E_{t,q(\mathbf x_1),p(\mathbf x_0)}\left[\left\Vert\mathbf v_{t}(\boldsymbol\psi_t(\mathbf x_0);\theta)-\frac{\mathrm d}{\mathrm dt}\boldsymbol\psi_t(\mathbf x_0)\right\Vert^2\right] \end{align} \] 这就是 flow matching 最终用于训练的损失函数形式。下面我们考察两种特殊情形。
特殊情形:经典扩散
若取 \(\boldsymbol\mu_t(\mathbf x_1)=\mathbf x_1,\,\sigma_t(\mathbf x_1)=\sigma_{1-t}\),则得到了 VE diffusion 的加噪过程: \[ p_t(\mathbf x\vert\mathbf x_1)=\mathcal N\left(\mathbf x;\mathbf x_1,\sigma_{1-t}^2\mathbf I\right) \] 此时条件流为: \[ \boldsymbol\psi_t(\mathbf x)=\sigma_{1-t}\mathbf x+\mathbf x_1 \] 若取 \(\boldsymbol\mu_t(\mathbf x_1)=\alpha_{1-t}\mathbf x_1,\,\sigma_t(\mathbf x_1)=\sqrt{1-\alpha_{1-t}^2}\),则得到了 VP diffusion 的加噪过程: \[ p_t(\mathbf x\vert\mathbf x_1)=\mathcal N\left(\mathbf x;\alpha_{1-t}\mathbf x_1,(1-\alpha_{1-t}^2)\mathbf I\right) \] 此时条件流为: \[ \boldsymbol\psi_t(\mathbf x)=\sqrt{1-\alpha_{1-t}^2}\mathbf x+\alpha_{1-t}\mathbf x_1 \] 可以看见,VE diffusion 或 VP diffusion 的条件流对时间 \(t\) 不是线性关系,也就是说它们的轨迹会拐弯。
特殊情形:最优传输
相比经典的扩散路径,一个更合适的路径是将 \(\boldsymbol\mu_t(\mathbf x),\,\sigma_t(\mathbf x)\) 都设置为 \(t\) 的线性变换: \[ \boldsymbol\mu_t(\mathbf x_1)=t\mathbf x_1,\quad \sigma_t(\mathbf x)=1-(1-\sigma_\min)t \] 这样得到的条件流为: \[ \boldsymbol\psi_t(\mathbf x)=(1-(1-\sigma_\min)t)\mathbf x+t\mathbf x_1 \] 该条件流事实上是两个高斯分布 \(p_0(\mathbf x\vert\mathbf x_1)\) 和 \(p_1(\mathbf x\vert\mathbf x_1)\) 之间的最优传输 displacement map. 直观上,该轨迹是一个匀速直线运动,如下图所示:
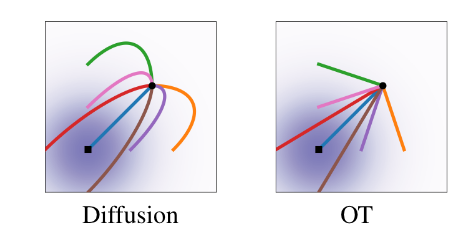
需要强调的是,“直线”路径只对于给定 \(\mathbf x_1\) 的条件下的条件流成立,在真正生成数据时粒子的“边缘流”依旧是曲线轨迹。
参考资料
- Lipman, Yaron, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling. arXiv preprint arXiv:2210.02747 (2022). ↩︎
- Chen, Ricky TQ, Yulia Rubanova, Jesse Bettencourt, and David K. Duvenaud. Neural ordinary differential equations. Advances in neural information processing systems 31 (2018). ↩︎
- Tor Fjelde, Emile Mathieu, Vincent Dutordoir. AN INTRODUCTION TO FLOW MATCHING. https://mlg.eng.cam.ac.uk/blog/2024/01/20/flow-matching.html ↩︎