[Stable Diffusion]webui部署(Linux) Github: https://github.com/AUTOMATIC1111/stable-diffusion-webui 更新日志 webui 项目更新频繁,不能保证本文内容仍然适用于后续版本。 2024.01.22:更新至 webui v1.7.0 版本 (commit hash 为 cf2772f) 2023.06.14:文章首次发布,基于 v1.3.2 版本 (commit ha 2023-06-14 AIGC #generative models #AIGC #stable diffusion
StyleGAN 系列 StyleGAN 如果要说 StyleGAN 的最大的贡献,无疑是改变了传统的生成器架构,通过把隐变量分层引入到 backbone 网络,揭示了网络的各层能够控制生成图像的不同抽象程度的语义,从而在一定程度上实现了无监督特征解耦。另外,作者提出的 FFHQ 数据集也是一个很大的贡献,在之后的生成模型研究乃至 low-level vision 领域中都经常用到。 网络架构设计 在 StyleGAN 2023-06-08 生成模型 > GANs #generative models
Midjourney 调研 官网 | 文档 特别说明:本文展示的所有图片都经过了大幅度的缩小和压缩处理,并非原图。 模型版本 使用 --version 或 --v 参数来指定版本。 v5.2:该版本有更好的颜色、对比度和结构,有略微更好的文本理解能力。对 --stylize 参数响应度更高。特别地,如果不想要 Midjourney 的默认审美风格,可以加参数 --style 2023-06-03 AIGC #generative models #AIGC
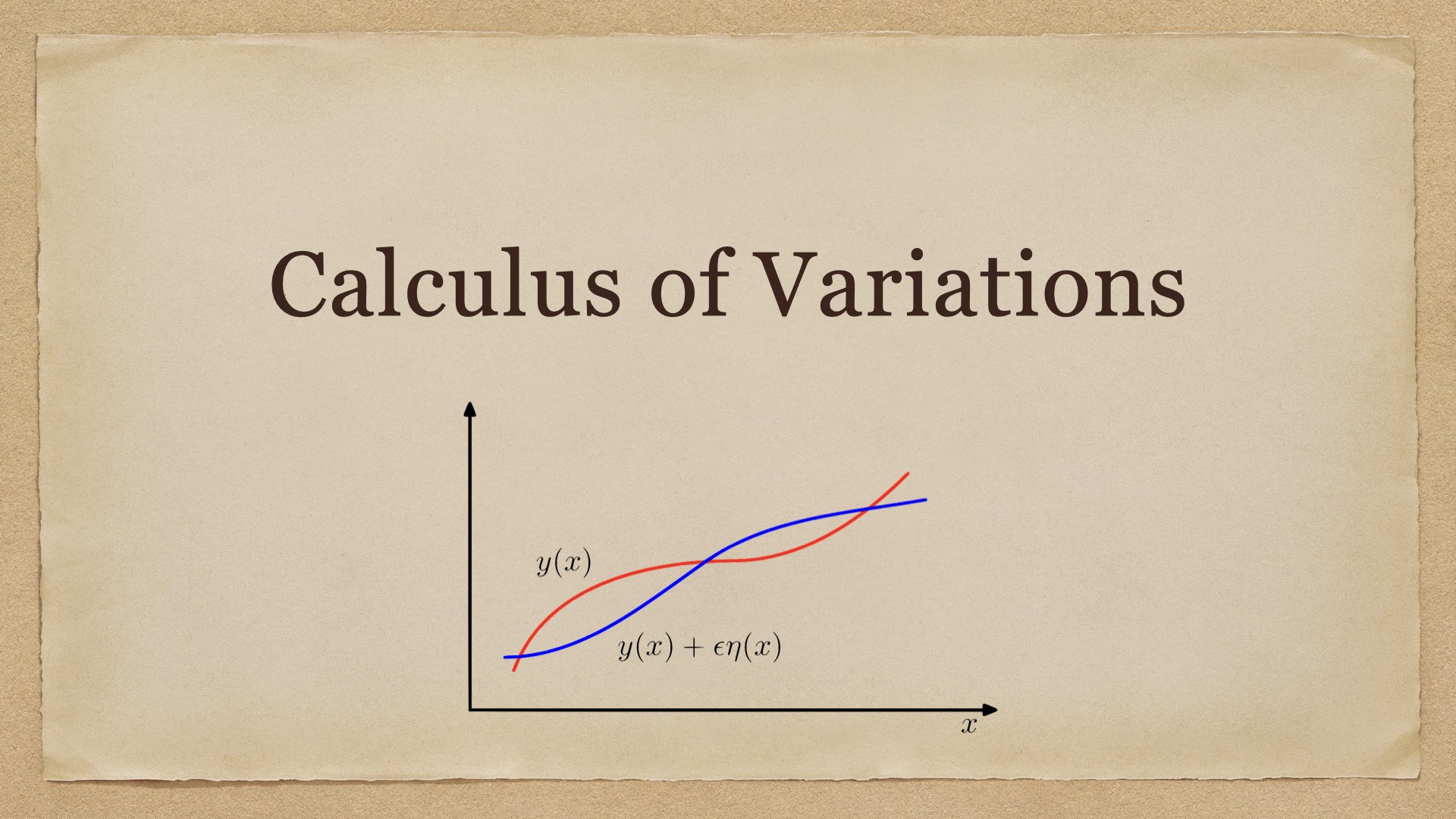
Calculus of Variations 泛函的概念 众所周知,函数是数到数的映射——输入为数值 \(x\),输出为数值 \(y(x)\). 将函数的概念进行扩展,定义泛函 (functional) 为函数到数的映射——输入为函数 \(y(x)\),输出为数值 \(F[y]\). 直观地讲,泛函就是“函数的函数”。 Example 1:给定平面上的两点 \((x_1,y_1),(x_2,y_2)\),穿过它们的路径有无数条。对其中某条路径 2023-04-25 机器学习 #machine learning
Vector-Quantized VAE/GAN/Diffusion VQ-VAE VQ-VAE 是 Google DeepMind 在 2017 年提出的一个类 VAE 生成模型,相比普通的 VAE,它有两点不同: 隐空间是离散的,通过 VQ (Vector Quantization) 操作实现; 先验分布是学习出来的。 为什么要用离散的隐空间呢?首先,离散的表征更符合一些模态的自然属性,比如语言,而由于图像也能在一定程度上用语言描述,因此使用离散表征并非不可 2023-03-29 计算机视觉 #generative models
扩散模型逆向方差的选取 \[ \newcommand{\x}{\mathbf x} \newcommand{\calN}{\mathcal N} \newcommand{\E}{\mathbb E} \] DDPM: 人为选取方差 首先做一个简要回顾。DDPM 定义前向马尔可夫过程为: \[ \begin{align} &q(\x_{1:T}\vert\x_0)=q(\x_0)\prod_{t=1}^T q(\x 2023-01-14 生成模型 > Diffusion Models #generative models
Diffusion Guidance \[ \newcommand{\x}{\mathbf x} \newcommand{\calN}{\mathcal N} \newcommand{\coloneqq}{\mathrel{\mathrel{\vcenter{:}}=}} \] Preface 我们在之前的文章中关注的都是无条件生成,生成结果不受我们控制,特别是以 DDPM 为代表的采样过程本身就带有随机性的模型,即使用同样的初始变量 2022-12-29 生成模型 > Diffusion Models #generative models
不止去噪!任意退化模式上的扩散模型 \[ \newcommand{\x}{\mathbf x} \newcommand{\E}{\mathbb E} \newcommand{\calN}{\mathcal N} \newcommand{\I}{\mathbf I} \newcommand{\coloneqq}{\mathrel{\mathrel{\vcenter{:}}=}} \] Cold Diffusion 站在 machine 2022-12-17 生成模型 > Diffusion Models #generative models
DDIM与加速采样 \[ \newcommand{\x}{\mathbf x} \newcommand{\I}{\mathbf I} \newcommand{\calN}{\mathcal N} \newcommand{\E}{\mathbb E} \] DDPM Recap 前向过程 设有一列 noise schedule:\(\{\beta_t\}_{t=1}^T\),记 \(\alpha_t=1-\beta_t 2022-12-14 生成模型 > Diffusion Models #generative models
搭建个人深度学习工作站(环境篇) 前言 硬件配置 主板:华硕 TUF GAMING B560M-PLUS WIFI CPU:Intel i7-11700 @ 2.50GHz 8核16线程 内存:英睿达 美光32GB(16Gx2)套装 DDR4 3600MHz GPU:NVIDIA RTX 3080Ti 硬盘: Samsung SSD 980 1TB x 2 WDC WD20EZBX-00A 2TB 电源:长城 猎金部落 额 2022-12-11 深度学习 #pytorch #linux
搭建个人深度学习工作站(操作系统篇) 说明:由于是个人使用,我安装的是 Windows + Ubuntu Server 双系统。用 Ubuntu Server 训练,用 Windows 摸鱼。 硬件配置 主板:华硕 TUF GAMING B560M-PLUS WIFI CPU:Intel i7-11700 @ 2.50GHz 8核16线程 内存:英睿达 美光32GB(16Gx2)套装 2022-12-11 深度学习 #pytorch #linux
扩散模型的SDE与ODE描述 \[ \newcommand{\x}{\mathbf x} \newcommand{\z}{\mathbf z} \newcommand{\E}{\mathbb E} \newcommand{\f}{\mathbf f} \newcommand{\w}{\mathbf w} \newcommand{\calN}{\mathcal N} \newcommand{\pdata}{p_\text{dat 2022-12-04 生成模型 > Diffusion Models #generative models
Score-Based Generative Models \[ \newcommand{\E}{\mathbb E} \newcommand{\pdata}{p_\text{data}} \newcommand{\x}{\mathbf x} \newcommand{\v}{\mathbf v} \newcommand{\R}{\mathbb R} \newcommand{\T}{\mathsf T} \] Brief Introduction 在从VAE 2022-10-13 生成模型 > Diffusion Models #generative models
从VAE到DDPM \[ \newcommand{\E}{\mathbb E} \newcommand{\KL}{\mathrm{KL}} \newcommand{\calN}{\mathcal N} \newcommand{\x}{\mathbf x} \newcommand{\z}{\mathbf z} \newcommand{\coloneqq}{\mathrel{\mathrel{\vcenter{:}}=} 2022-09-29 生成模型 > Diffusion Models #generative models
Variational Autoencoder 核心思想 VAE 是一种基于隐变量的生成模型,它将隐变量 \(\mathbf z\in\mathbb R^d\)(一般采自正态分布)映射到 \(\mathbf x\in\mathbb R^D\),并希望 \(\mathbf x\) 的分布尽可能接近真实数据的分布。这个映射不是确定性的,可以写作概率分布 \(p_\theta(\mathbf x\vert \mathbf z)\),其中 \(\the 2022-09-17 生成模型 > VAEs #generative models
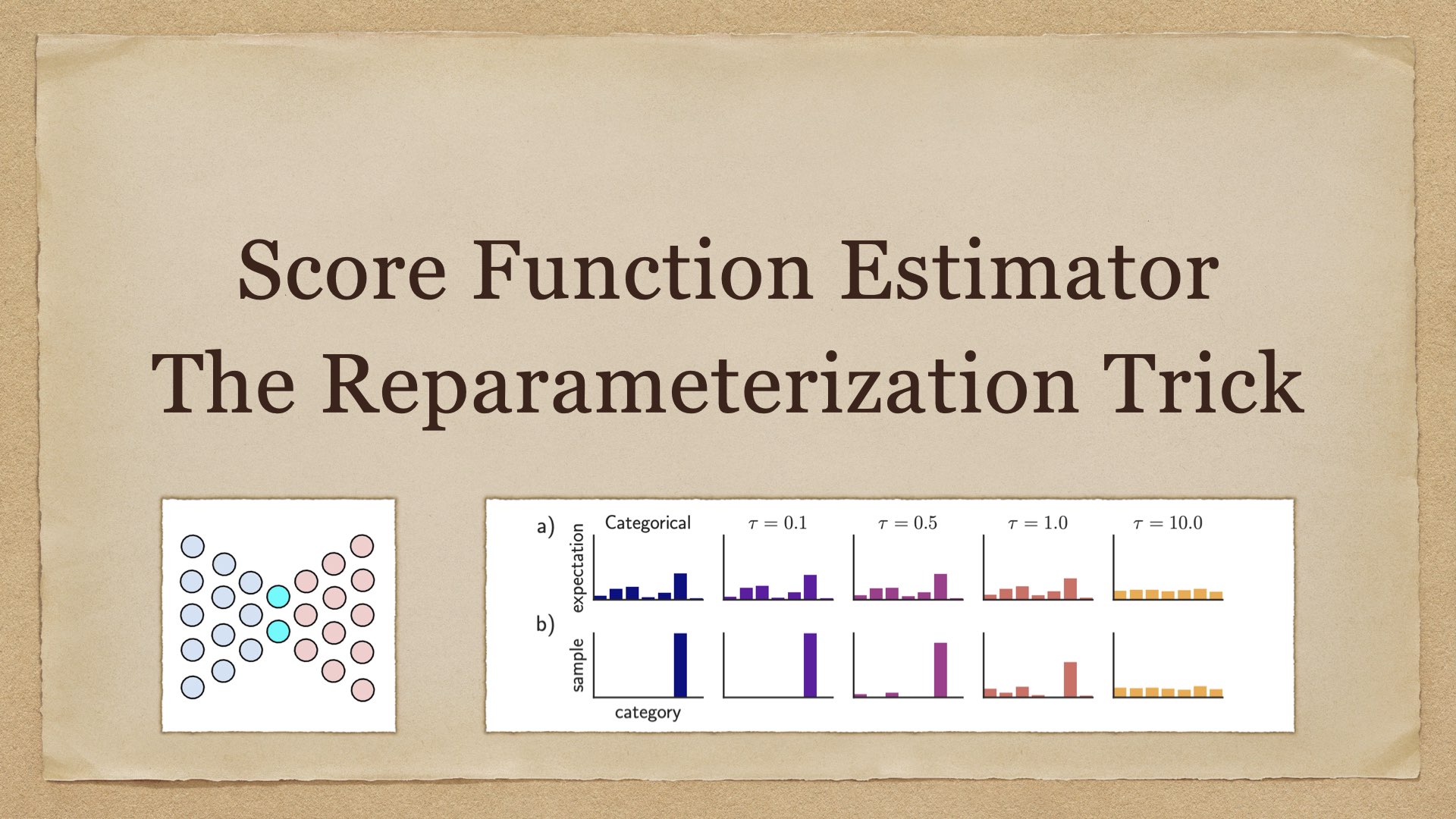
Score Function Estimator and Reparameterization Trick The Problem 许多机器学习/深度学习问题的优化目标为如下形式: \[ \mathbb E_{z\sim \mathcal P}[f_\theta(z)]\tag{1}\label{1} \] 训练时用蒙特卡洛采样近似期望: \[ \mathbb E_{z\sim\mathcal P}[f_\theta(z)]\approx\frac{1}{N}\sum_{n=1}^N f_\theta( 2022-09-06 机器学习 #machine learning
k-means Algorithm 谈到聚类,k-means 无疑是最先想到的算法之一了。其思想异常的简单有效,但隐藏着许多值得深入探究的奥秘。 k-means 理论推导 设有样本集 \(\{\mathbf x_1,\ldots,\mathbf x_N\}\),其中 \(\mathbf x_n\in \mathbb R^d\);又设 \(C:\mathbb N\to\mathbb N\) 表示对样本集的一个划分,\(C(n)=k\) 2022-09-04 机器学习 #machine learning
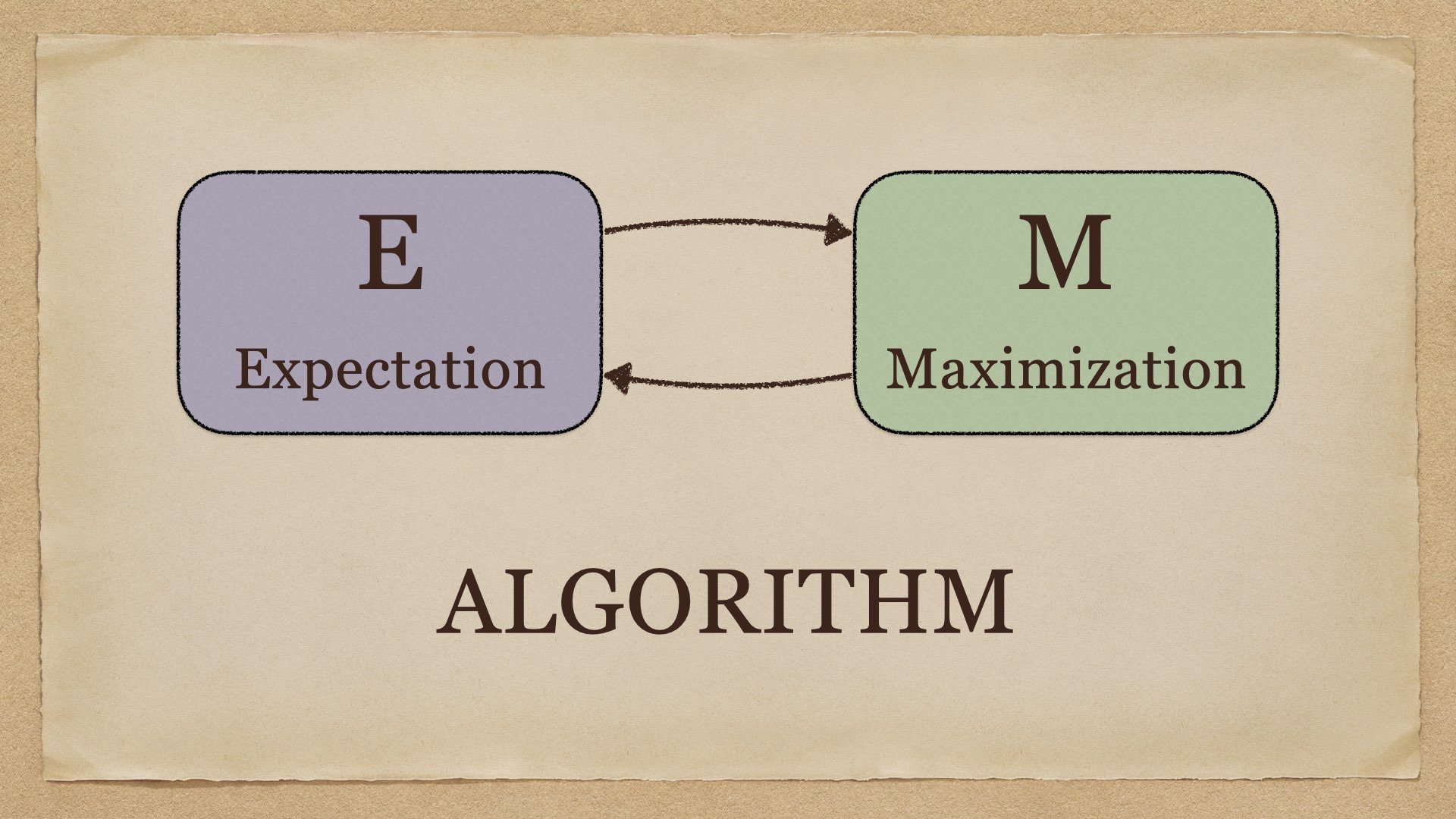
EM Algorithm EM 算法是极大似然法的推广,用于解决存在隐变量(hidden variables / latent factors)的参数估计问题。 问题描述 极大似然法是最常用的参数估计方法之一。设观测样本集为 \(\{\mathbf x_n\}_{n=1}^N\),模型参数为 \(\theta\),则对数似然为: \[ L(\theta)=\log\prod_{n=1}^Np_\theta(\mathbf 2022-08-23 机器学习 #machine learning
PyTorch单机多卡从入门到入土(坑点记录) 在 Vision 里用上 Transformer 之后,单卡训练连两位数的 batchsize 都开不了,必须得学学单机多卡的使用了。 PyTorch 中,多卡训练有两种方案: DataParallel:只支持单机多卡,代码很方便,只需要添加一行,但是效率比较低,不推荐使用 DistributedDataParallel:支持多机多卡,效率高,但是要折腾一下代码 基于性能考虑,一般我们会选择第 2022-08-18 深度学习 #deep learning #pytorch
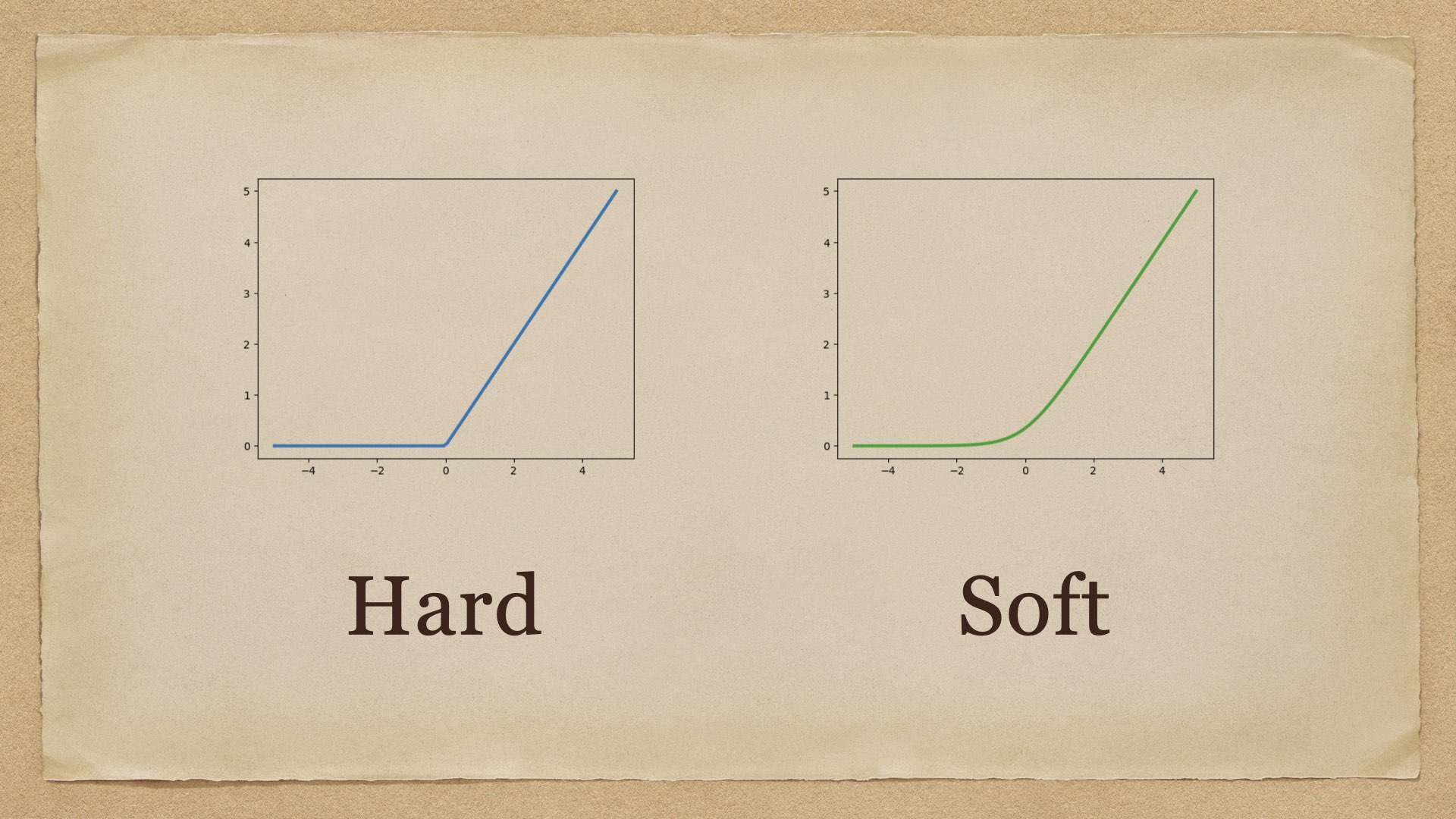
各种函数的hard与soft形式 max 与 logsumexp 一个常见的误解是:\(\text{softmax}\) 是 \(\max\) 的 soft 版本,但其实稍微想一下就知道这是不对的——\(\max\) 函数的输出是一个实数,而 \(\text{softmax}\) 的输出是一个向量,一个向量怎么可能去近似一个实数呢? 事实上,\(\max\) 函数的 soft 版本是 \(\text{logsumexp}\) 函数 2022-07-25 机器学习 #machine learning
![[Stable Diffusion]webui部署(Linux)](/blog-main/gallery/cover/stability.jpg)